
Interpreting the stats/results.
The stats region contains three major categories. Being able to correctly interpret them will help you understand how many duplicates you have to deal with.
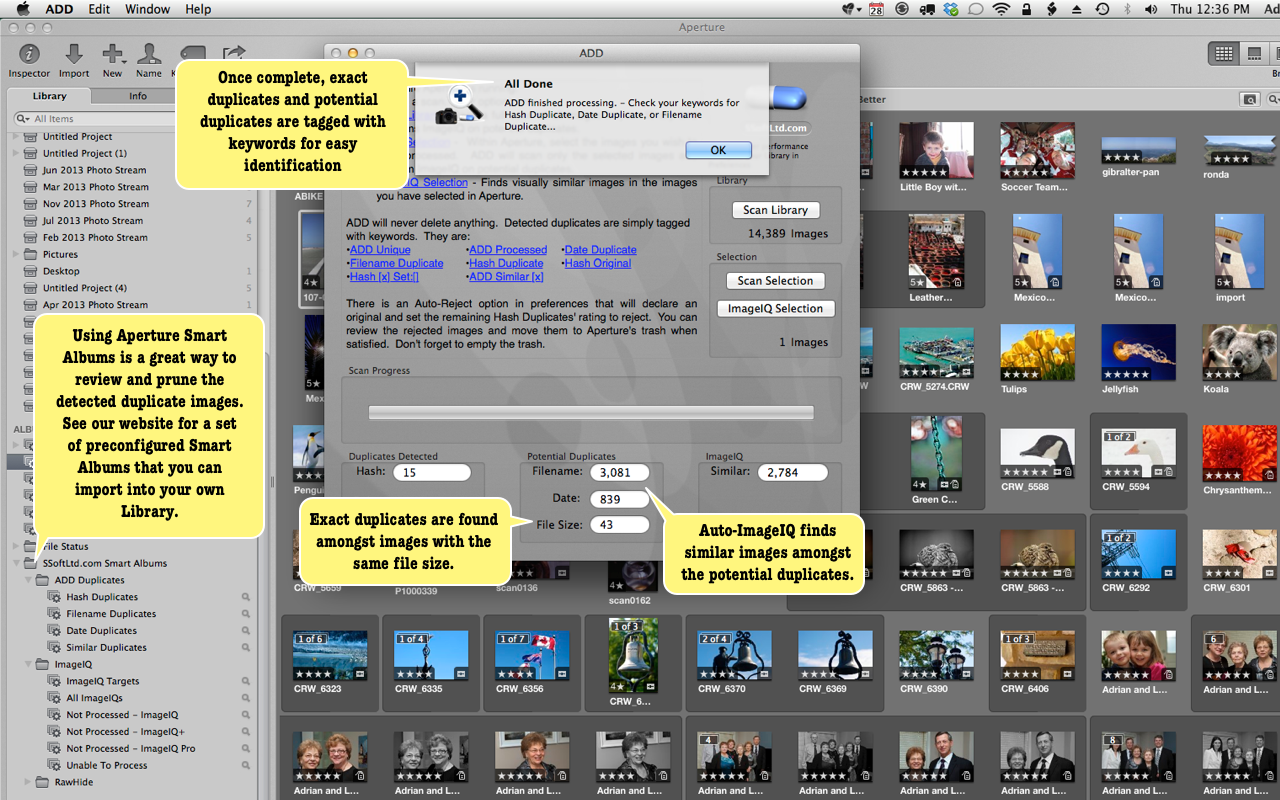
Potential Duplicates
This region indicates the number of potential duplicates in your library. These potential duplicates are used to inform ADD that these images need to be further inspect.
In particular, the File Size potential duplicates are fed to the exact duplicate detection process. The Filename and Date potential duplicates are fed to ImageIQ for processing.
Furthermore, the filename and date potential duplicates are tagged with the "Filename Duplicate" and "Date Duplicate" keywords.
Duplicates Detected
In this section the number of exact duplicates found are displayed beside the "Hash" label. These images will receive the "Hash Duplicate" keyword.
If you have used the "Auto-Reject" option, the count of images whose ratings were set to reject are displayed underneath the Rejected label.
ImageIQ
ImageIQ takes the potential Filename and date duplicates and further analyses them to see if they are similar. Similarity means that they could be scaled, rotated, or colour correct versions of the same image. The count here indicates the number of images that received the "ADD Similar [x]" keywords, where [x] indicates how strong the similarities are. For example, “ADD Similar 0” are images which are most similar and “ADD Similar 8” show weaker similarities.